Kevin Kononenko 의 Web Caching Explained by Buying Milk at the Supermarket를 번역한 글입니다
슈퍼마켓에서 우유를 사 보신적 있다면, 서버와 브라우저 양쪽의 캐싱 개념을 이해하실 수 있습니다.
여러분이 인터넷을 열심히 사용하고 있다면(아마 그렇겠죠), 캐싱의 덕을 톡톡이 보셨을 겁니다. 하지만 언제 어떻게 이 마법같은 일이 일어나는지 잘 알고 계실지 모르겠습니다.
개발자의 관점에서 본다면 캐싱은 높은 성능의 웹 애플리케이션과 웹 서버를 더 쉽게 만들어주는 역할을 합니다. 매번 몰려드는 수천 개의 요청을 처리하느라 서버를 최적화하는 방법을 고민하는 대신에, 개발자들은 캐싱 프로토콜을 구현해서 훨씬 쉽게 문제를 해결할 수 있습니다.
캐싱은 페이지를 로드하는데 고작 1 초에서 2 초 정도의 시간만 줄일 수도 있습니다. 그럴 때는 약간 .. 덜 대단하게 느껴지겠죠. 하지만 캐싱은 많은 수의 사용자를 처리하기 위해서 반드시 필요합니다.
예전 웹 애플리케이션에 캐싱을 적용하고 나서 저는 단순히 용어를 설명하는데 그치지 않고 더 나은 방식으로 설명해야 한다는 깨달음을 얻었습니다. 그러다가 냉장고에 들어있는 우유가 ‘처음 생산되어 집의 냉장고까지 오게 된 과정’ 이 캐싱을 설명하는데 꽤 잘 맞아떨어진다는 생각이 들었습니다.
이 가이드를 이해하시려면 그저 웹 서버에 대해 간단한 이해만 있으면 됩니다. 한번 보시죠!
인터넷에 캐싱이라는 개념이 없다면 어떻게 되었을까?
본격적으로 캐싱을 이해하기 전에, 이 캐싱이라는 개념이 없다면 인터넷이 어땠을지 생각해봅시다. 1700 년대에서 1800 년대 시골에 살고 있다는 상상을 해 보세요. 여러분은 농장을 가지고 있는데, 당연히 냉장고는 없습니다. 소가 몇 마리 있긴 하지만 우유를 짜 내어도 금방 상해 버리기 때문에 상품 가치가 떨어집니다.
토막 상식: 일부 문화권은 아직도 냉장 개념이 없습니다. 그래서 소에게서 짜낸 우유를 바로 마시거나, 곡물과 섞어 발효시킵니다. 흥미롭군요.
어쨌든, 우유를 마을에 내다 팔고 싶지만 아주 제한된 시간 안에 팔 수밖에 없습니다. 소 한마리가 하루에 1 갤런의 우유를 만들어낼 수 있다고 해 봅시다. 그런데 너무 많은 사람들이 우유를 사러 온다면 일단 일부만 준 다음에 나머지는 내일 찾으러 오라고 해야 할 겁니다.

그리고 배급 가능한 양에 한계가 있기 때문에 소를 더 들여놓을 수도 없습니다. 여러분의 마을에 있는 사람들만 우유를 구입하고 있기 때문에 확장 가능한 범위가 명확합니다.

캐싱을 하지 않은 상태에서, 서버의 컴퓨팅 파워는 한계가 있습니다. 캐싱은 주로 아래와 같은 정적 자료(static assets)들을 불러오는데 사용됩니다.
- 이미지 파일
- CSS 파일
- HTML 파일
- 자바스크립트 파일
서버는 기본적으로 매 요청마다 새로운 응답을 돌려주어야 합니다. 하지만 실제로 페이지를 불러오기 위한 요청은 달랑 하나가 아니라 위의 4 가지 카테고리에 있는 파일들을 각각 요청하는 경우가 많습니다. 거대한 이미지 파일을 처리하는데 시간이 오래 걸린다면 서버는 전세계에서 몰려드는 수 많은 사용자들 덕에 버벅이게 됩니다. 결과적으로 사용자들은 페이지가 불러와질 때 까지 아주 오랜 시간 기다려야 할 수도 있습니다.
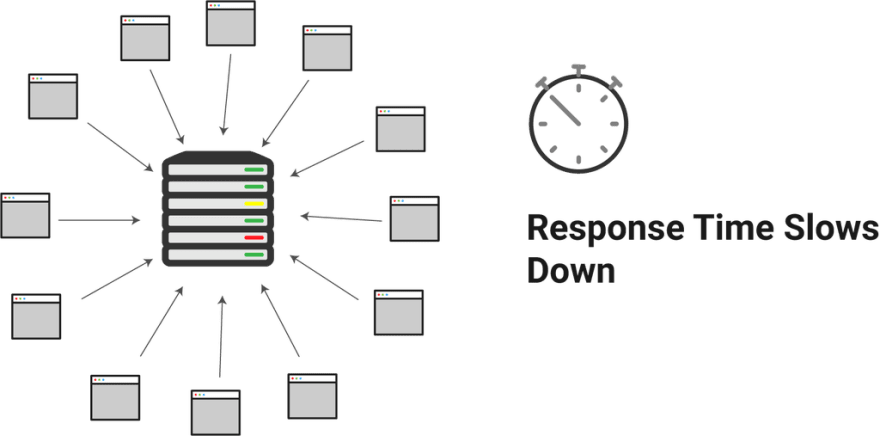
이상적인 방법은 일반적인 요청에 따른 응답을 미리 저장하여 서버에 직접 부담을 주는 요청을 줄이는 것입니다. 서버는 개별 요청을 매번 처리할 필요가 없이, 캐시가 바로 응답을 합니다. 서버를 증설하는 방법도 있지만 엄청난 금전적 부담이 될 겁니다.
서버 사이드 캐싱이란?
위의 농장 시나리오로 돌아가서, 낙농가를 성공적으로 운영하는 방법을 알게 되셨나요?
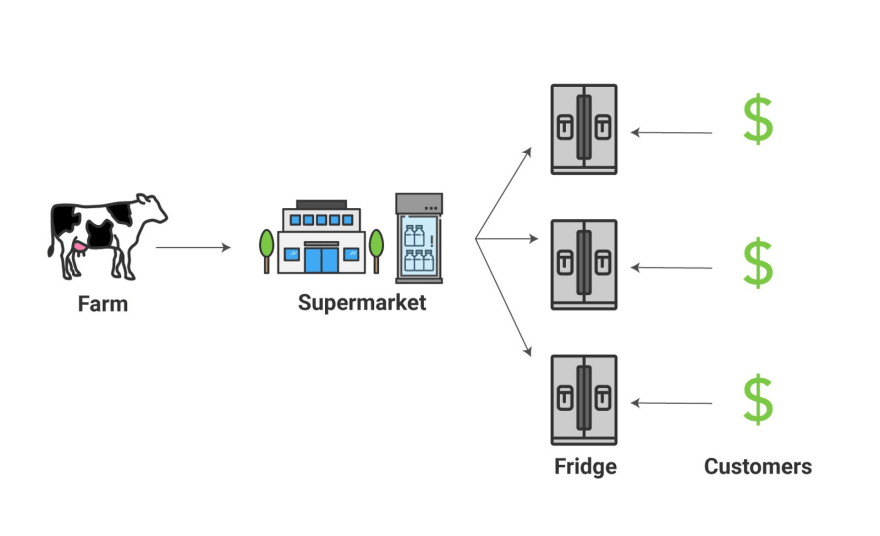
바로 냉장 시설이 있는 슈퍼마켓을 활용하는 겁니다!
이렇게 해야 사람들은 바로바로 우유를 마시기 위해 농장에 직접 올 일도 없으며, 우유도 한 번 생산하고 2 주정도는 거뜬히 보관할 수 있습니다.
슈퍼마켓 덕에 농장의 부담은 크게 줄어들었습니다. 소가 언제나 우유를 바로 생산해야할 필요가 없어졌기 때문입니다. 슈퍼마켓은 소비자의 요청을 바로 처리할 수 있습니다. 여러분은 그저 매일 소가 알맞은 양의 우유를 만들어내도록 관리하면 됩니다. 게다가 마을 주변에 있는 모든 주민들도 우유를 살 수 있습니다. 언제나 슈퍼마켓 냉장고 안에 우유가 들어있으니까요.
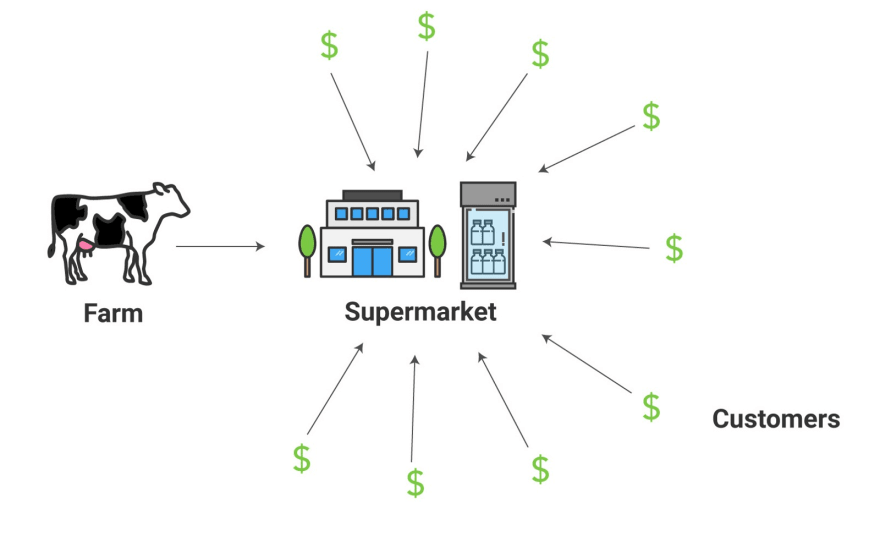
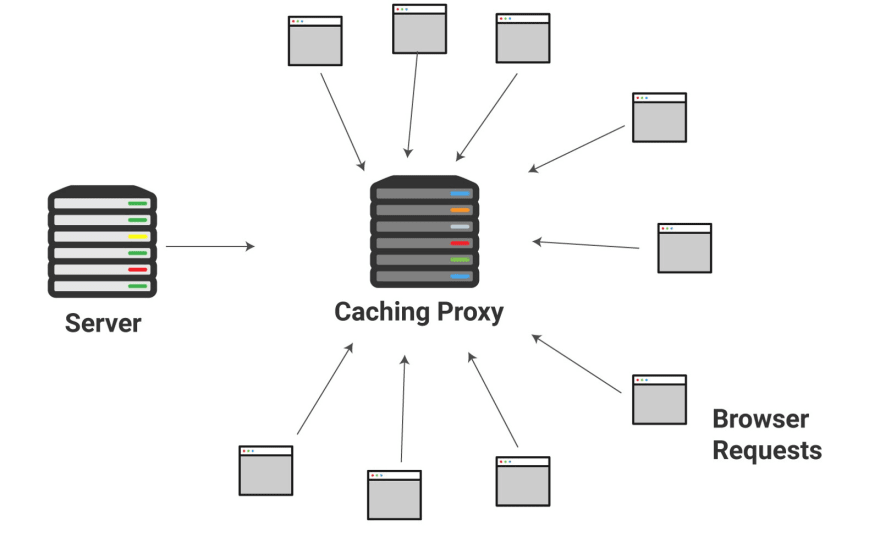
슈퍼마켓처럼 서버 사이드 캐시는 일반적인 요청을 바로 처리하여 컨텐츠를 더 빠르고 안정적으로 전달할 수 있습니다.
위의 이미지에서 저는 캐싱 프록시(Caching proxy) 라는 용어를 사용했습니다. 캐싱 프록시는 정적 파일을 저장해두고 이 파일들을 찾는 요청에 응답하는 서버입니다. 공통된 요청을 가로채서 빠르게 응답하는거죠. 이렇게 메인 웹 서버에 들어가는 부담을 줄일 수 있습니다.
슬슬 몇 가지 질문이 떠오르실 겁니다.
- ”공통된/일반적인” 요청이라는 걸 어떻게 정의하지?
- 프록시 서버는 캐시를 얼마나 유지할까?
위의 질문에 답변하려면 캐싱을 설정하는 법 부터 시작하는 더 긴 튜토리얼을 써야겠지만, 지금은 일단 신선도라는 개념을 우선적으로 숙지하시길 바랍니다. 캐싱 프록시는 서로 다른 시간에 캐싱된 각각 다른 파일을 가지고 있으며, 언제까지 이 파일을 전달해야할지 지정해야 합니다. 이 부분은 여러분의 **캐싱 정책(Caching policy)**에 달려있습니다.
이 부분도 슈퍼마켓에 들어있는 우유에 비유할 수 있습니다. 슈퍼마켓 관리자는 우유를 얼마나 오래 보관하고 있다가 버릴 지 결정해야 합니다. 캐싱 프록시는 캐시 적중률(cache hit ratio, 캐싱 서버가 전달할 수 있는 컨텐츠의 비율)이라는 개념을 통해 얼마나 성공적으로 캐시들이 전달되는지 측정합니다.
CDN 이란?
아직까진 슈퍼마켓 하나가 여러분의 우유를 판매하고 있습니다. 큰 진전이긴 하지만, 이 상점 범위의 바깥에 있는 사람들에게는 우유를 판매할 수 없습니다. 판매량을 늘리고 싶다면 더 많은 상점에 우유를 납품해야 합니다.
그래서 더 많은 수퍼마켓에 우유를 공급하여 더 넓은 지리적 범위에 위치한 사용자들을 만족시킬 수 있게 되었습니다. 이 형태는 CDN(content delivery network)과 유사합니다. CDN 은 전 세계에 위치한 프록시 서버(위에서 이야기한 캐싱 프록시)의 묶음입니다.
일반 사용자들은 보통 인터넷 속도가 빠르니까 대부분의 사이트가 빨리 불러와진다고 느낄 수 있습니다. 하지만 실제로는 CDN 이 정적 파일을 빠른 속도로 전달해주니까 빠른 속도를 느낄 수 있는겁니다!
만약 여러분이 영국에 있고 미국 버지니아에 위치한 서버에 캐시된 파일을 불러오려는 경우, 처음 시작된 신호가 수천 마일의 케이블을 타고 오느라 약간의 지연을 느낄 수 있습니다. 만약 영국 지역에 있는 프록시에 접근할 수 있다면 훨씬 빠르게 파일을 불러올 수 있습니다.
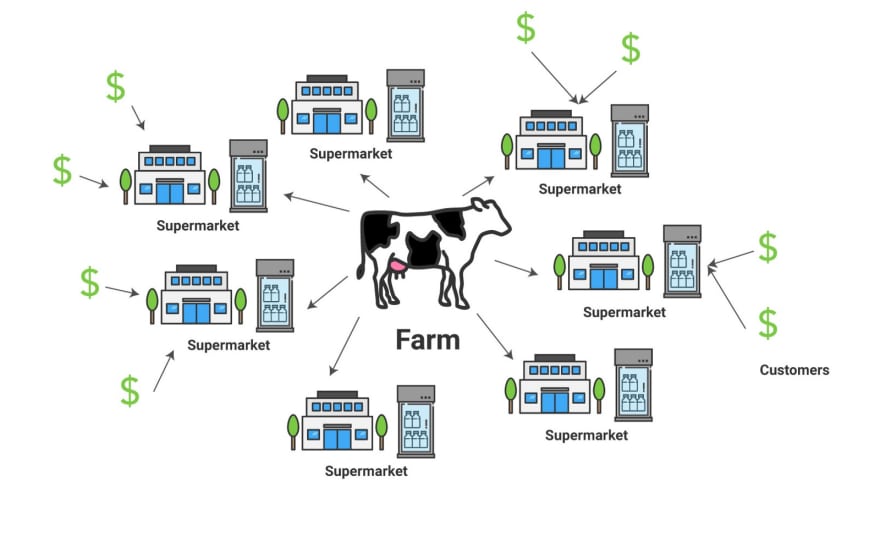
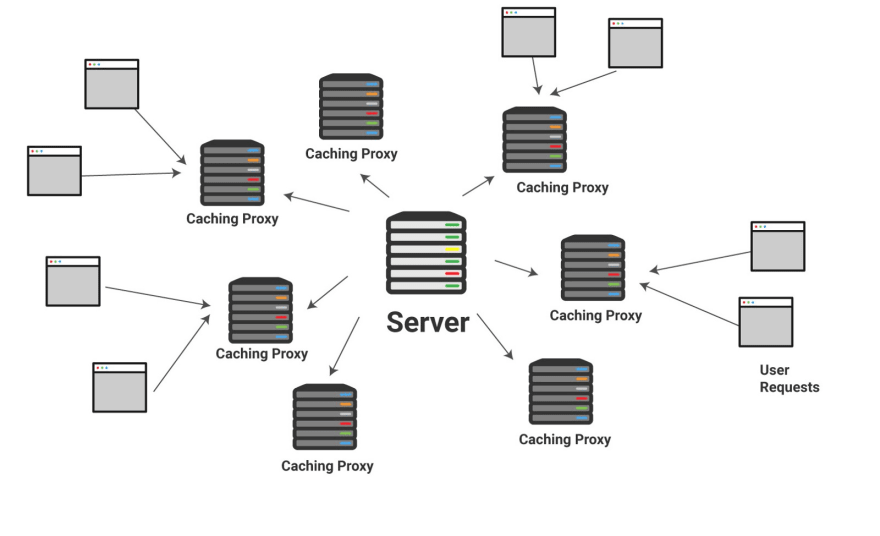
따라서 메인 서버는 정적 자료 사본을 CDN 네트워크 내의 프록시 서버들에게 전송할 수 있으며 더 이상 자료가 신선하지 않을 때까지 그 지역의 요청을 신속하게 처리 할 수 있습니다. 일반적인 CDN 제공 업체에는 Rackspace, Akamai 및 Amazon Web Services 가 있습니다.
브라우저 캐싱은 어떻게 되죠?
이제 외국에 있는 사람들도 여러분의 농장에서 만들어진 시원한 우유를 집에서 마실 수 있게 되었습니다. 하지만 아직 문제가 하나 남아있는데, 이 사람들은 집에 우유를 보관할 방법이 없습니다. 소비자들은 여전히 우유를 사고 나서 최대한 빨리 마시고, 다시 식료품점에 가서 새 우유를 사야합니다. 아직 전체 유통망이 소비자들에게 좋게 돌아가지 않고 있네요.
해결책은 뭘까요? 냉장고죠!
냉장고를 사용하면 우유를 사서 집에 저장할 수 있고, 슈퍼마켓에 자주 왔다갔다할 필요가 없습니다. 캐싱 용어로 말씀드리자면 여태까지 이야기 한 곳과는 전혀 다른 곳, 즉 클라이언트에도 정적 자료를 저장하는 겁니다. 클라이언트라 함은 브라우저로 접속한 컴퓨터를 일컫습니다. 이전에 이야기하던 프록시 서버는 원격에 위치해 있었습니다.
이 방식은 Facebook 이나 Amazon 같이 자주 접속하는 사이트에 아주 효과적인 방식입니다. 그 회사들의 서버 비용을 줄이는데도 도움이 되겠죠. 엄청난 양의 요청을 줄일 수 있으니까요.
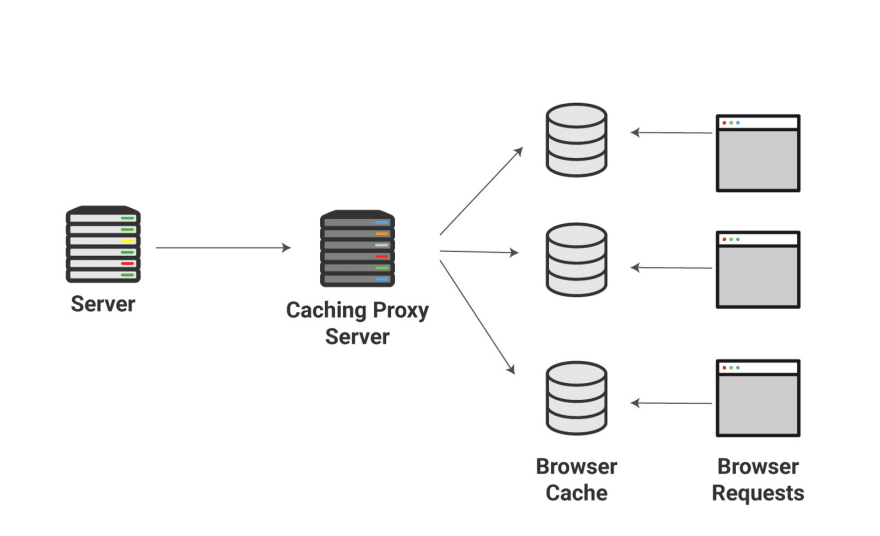
잊지 마셔야 할 점이 있는데, 우리는 마법처럼 집에 있는 냉장고에 우유가 뿅 하고 나타나는 상황에 대해 이야기하는게 아닙니다! 여러분은 여전히 실제 서버나 프록시 서버로 전달되는 요청을 보내야 합니다. 그리고 나서야 일부 파일을 로컬 머신에 저장할 수 있는거죠.
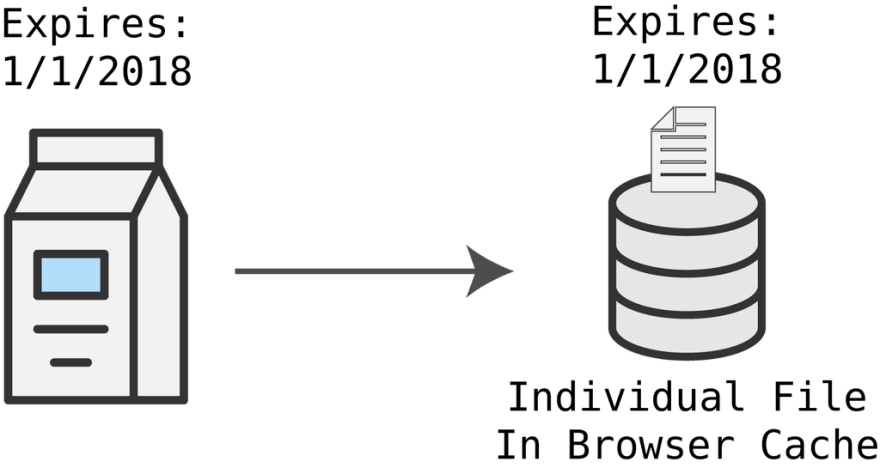
어떻게 브라우저는 언제쯤 새 파일을 서버로부터 받아올지 알고 있을까요? 만약 그렇지 않다면 절대로 업데이트된 파일을 받지 못하게 될 텐데요.
우유 생산자들이 우유곽에 적어둔 유통기한처럼, 서버는 HTTP 응답 헤더에 일부 식별자를 추가할 겁니다. 실제로는 HTTP 캐싱 주기를 설정하는데 4 가지 방법이 있지만 위의 시나리오는 유효기간을 설정하는 방법과 유사하다고 보시면 됩니다. 일부 다른 방법을 사용할 경우 서버와 통신해서 캐시의 유효성을 확인하기도 합니다.
언제 캐싱을 해야하나
처음 웹 애플리케이션을 만든다고 생각해보면, 수 천명의 사용자가 몰려들 때까지는 캐싱에 대해 전혀 생각할 필요가 없습니다. 아직 서버에 들어가는 부담이 적기 때문입니다. 하지만 스케일을 확장하면서 앱이 빨리 뜨도록 캐싱을 구현해야 할 필요가 있습니다.
Heroku의 예를 들자면 이 시스템은 처음 애플리케이션을 배포하기에 최적의 서비스지만, Amazon CloudFront 나 CloudFlare 등으로 별도의 서비스로 캐싱을 구현하도록 안내하고 있습니다. 이 서비스들을 활용하려면 시간을 좀 들여서 알아보셔야 합니다.
브라우저를 살펴보면 여러분은 새 정적 자료를 불러오기 위해 페이지를 새로고침 해도 페이지가 바뀌지 않는 상황을 겪기도 합니다. 아무리 새로고침 버튼을 눌러도 아무것도 바뀌지 않습니다.
보통 브라우저의 캐싱 프로토콜 때문에 생기는 문제인데, 브라우저 캐시를 무시하고 새로 서버에 자료를 요청하려면 Cmd+Shift+R(Mac) 이나 Ctrl+Shift+R(PC) 키를 눌러서 페이지를 다시 불러오면 됩니다.
웹 개발을 할 때 기본 중의 기본이지만 대충 알고 넘어갔던 캐싱을 아주 깔끔하게 설명한 글이었습니다. 본문에 있는 캐싱과 관련된 다양한 링크도 살펴보시며 지식을 확장하면 HTTP 캐싱에 대해 금방 이해하실 수 있으리라 생각합니다.
참고자료